是一種將檢索與生成結合的技術,用於增強生成模型的能力,特別是在需要從大量資料中檢索相關資訊並生成高質量文本的情境下。
檢索 (Retrieval):
在這個步驟中,系統會根據用戶的查詢(query)從資料庫或知識庫中檢索出與查詢最相關的文檔或片段。這通常涉及到使用向量搜索技術,將查詢和文檔表示為向量,並根據相似度找到相關的內容。
生成 (Generation):
接著,生成模型(如 GPT 系列模型)會基於檢索到的文檔生成最終的回答或文本內容。這個步驟的生成模型會將檢索到的文檔作為上下文來生成更準確和相關的回答,而非僅僅依賴預先訓練的模型權重來生成。
查詢輸入 (Query Input):
用戶提出一個查詢,這個查詢可能是問題、指令或需要生成內容的請求。
檢索階段 (Retrieval Phase):
查詢被轉換成向量形式,然後系統會在資料庫中進行向量搜索,找到與查詢最相似的文檔片段。
生成階段 (Generation Phase):
系統將檢索到的相關文檔提供給生成模型,生成模型基於這些文檔進行上下文理解,並生成符合用戶需求的文本內容。
問答系統: RAG 可用於建立智能問答系統,特別是當資料庫包含大量文檔時,它能檢索相關文檔來生成精確的回答。
內容生成: 在需要創建長篇文本(如報告、文章)且需要基於現有資料生成新內容時,RAG 能夠提供上下文相關的資訊來豐富內容。
聊天機器人: RAG 能夠提高聊天機器人的應答準確度,因為它可以根據用戶的對話上下文檢索相關信息,並生成更自然和相關的回應。
上下文相關性強: RAG 結合了檢索和生成的優點,生成的文本更貼近用戶需求,因為生成過程中考慮到了相關文檔內容。
可應用於未見過的知識: 由於檢索階段可以獲取實時資料,RAG 系統可以更好地應對涉及未見過的新知識或資料的查詢。
靈活性: RAG 可以適應不同類型的數據源,無論是結構化還是非結構化的資料,這使得它在多種應用場景下都非常有效。
檢索系統的效率: 檢索系統需要在大規模資料集中高效找到相關文檔,這對系統的性能要求較高。
生成模型的準確性: 儘管 RAG 能夠增強生成模型的表現,但生成模型仍可能出現理解錯誤或生成不符合上下文的內容。
RAG 是一種將檢索技術與生成技術結合的創新方法,通過檢索相關的文檔並基於這些文檔生成回答或文本,能夠在多種應用中提供更加精確和相關的內容。RAG 在問答系統、內容生成和聊天機器人等領域具有廣泛的應用前景,並且在處理大規模知識庫時展現了優異的表現。
我們將根據此篇論文,去介紹幾種RAG的方法
Retrieval-Augmented Generation for Large Language Models: A Survey


主要分成三個部分:
- Indexing (索引)
- Retrieval (檢索)
- Generation (生成)
Steps:
- 文件處理: 先將文檔進行處理分割成許多chunks(小塊)
- 向量化: 將chunks 編碼成向量(embeddings),並儲存在向量數據庫中,可增強後續進行相似檢所的效率
- 問題查詢: 用戶輸入問題
- 相關文獻檢索: 系統會使用user的query 與從vector database中檢索出與問題最相關的K個chunks 進行similarity 計算
- 合成提示: 將原始問題和retrieval 到的相關chunks作為上下文一同輸入到LLM中
- 回答生成: LLM再根據這些上下文生成出最終的答案
| 有RAG | 無RAG |
|---|---|
| LLM可以提供更詳細和準確的回答,因為它整合了外部的相關知識 | LLM可能無法提供有用的回答,因為它缺乏最新的、相關的信息 |
克服 Naive RAG 的局限性。它主要聚焦於提升檢索質量,並採用了預檢索和後檢索策略
在預檢索過程中,主要目標是優化索引結構和原始查詢
在檢索到相關內容後,關鍵是有效地將其整合到查詢中
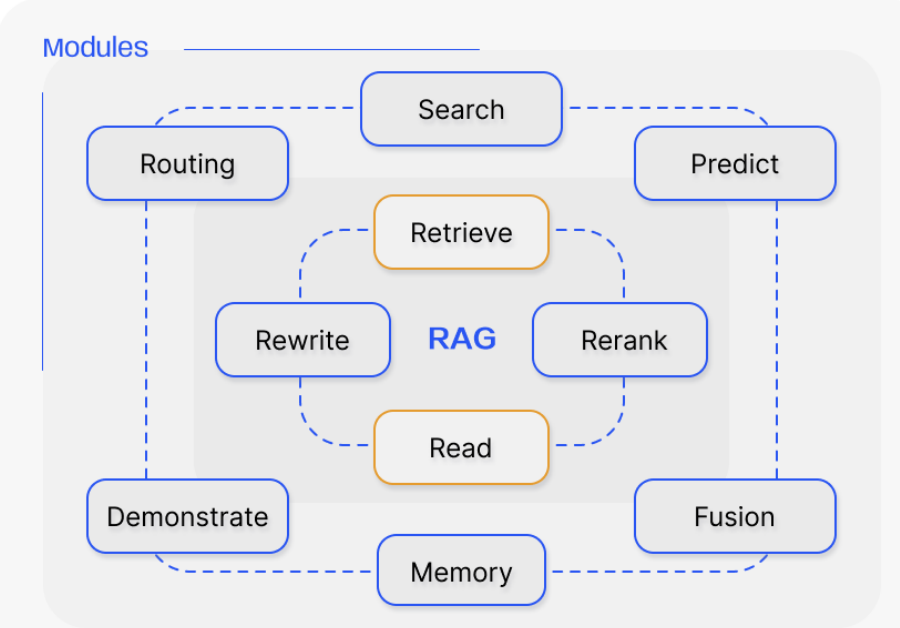
提供了更強的適應性和多樣性。它通過添加新的模塊和重新組織現有模塊來改善檢索和生成過程,以應對具體的挑戰
模塊化RAG引入了專門的組件來增強檢索和處理能力,這些模塊包括:
模塊化RAG允許模塊替換或重新配置,以應對特定挑戰,展示了其顯著的適應性。這超越了Naive RAG和Advanced RAG的固定結構,如“檢索”和“閱讀”機制。
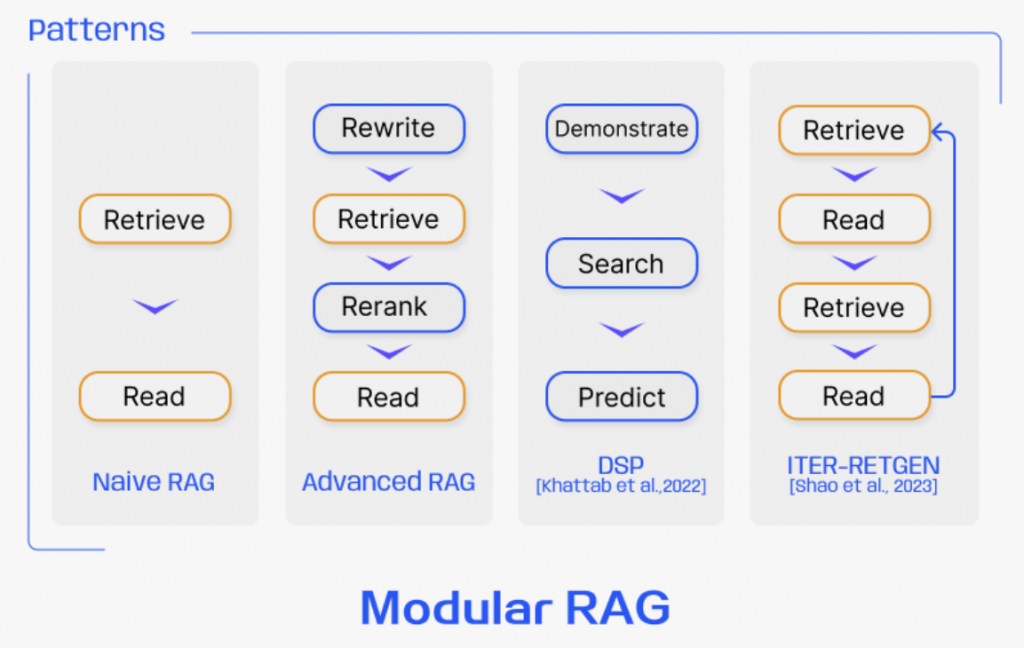
模塊化RAG的靈活安排展示了適應性檢索的優勢,如FLARE和Self-RAG技術。這種方法超越了固定的RAG檢索過程,根據不同場景評估檢索的必要性。
接下來,將會詳細介紹Naive RAG和Advanced RAG的方法&如何實作!